Watchlog AI-Traces
Monitor AI model calls—inputs, outputs, latency, and errors—across services in real time.
30-day trial on paid features. No credit card to start.
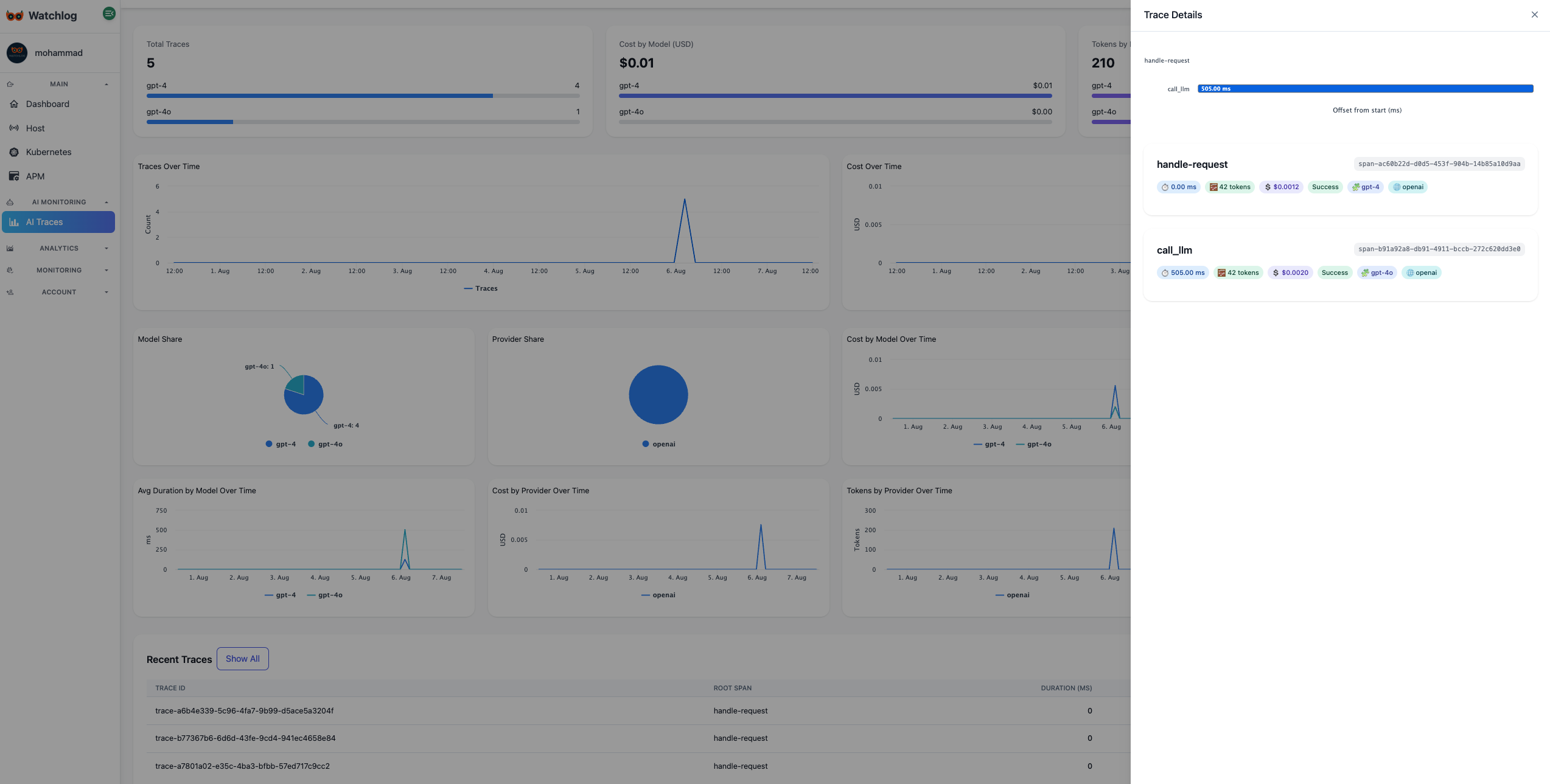
Why use AI-Traces?
- Capture prompts / inputs and responses / outputs for every AI request.
- Measure latency, token usage, throughput, and cost by model & route.
- Detect errors and anomalies with thresholds and smart routing.
- Analyze usage trends over time and compare models side-by-side.
Everything you need to observe AI
Prompt & response capture
Record structured inputs/outputs with optional field-level redaction.
Latency & error analytics
Track p50/p90/p99, error codes, and failure hotspots across endpoints.
Tokens & cost by model
Attribute token usage and spend to models, teams, and routes.
Model comparison
Compare error rate, latency, and cost across model providers.
Smart alerts
Thresholds with dedupe; route to Slack, Telegram, or Webhooks.
Team & audit
Invite teammates, share dashboards, and audit configuration changes.
SDKs & Documentation
JavaScript / TypeScript
Integrate AI-Traces to capture prompts, responses, latency, tokens, and costs from server routes and workers.
View documentationPython
Add AI-Traces to Python services to stream inputs/outputs and performance with minimal overhead.
View documentationBefore vs. after AI-Traces
- No visibility into prompts/responses
- Latency spikes discovered late
- Unclear cost and token usage
- Full trace of inputs/outputs
- Real-time latency & error tracking
- Cost and tokens by model/route
Get started in seconds
Follow our quickstart guide to integrate AI-Traces into your service.
View setup instructionsFrequently asked questions
What does AI-Traces capture?
Prompts/inputs, responses/outputs, latency, token usage, cost, and error details per request.
Which SDKs are available?
Node.js (JavaScript/TypeScript) and Python SDKs with simple initialization.
How do you handle sensitive data?
Enable field-level redaction and masking; TLS enforced in transit.
Can I alert on anomalies?
Yes, configure thresholds and route alerts to Slack, Telegram, or Webhooks with deduplication.
Need help integrating AI-Traces or have questions?
Contact us